原文:Arm Announces Mali-G76 GPU: Scaling up Bifrost
两年前,Arm 发布了一个全新的 GPU 架构:Bifrost ,以及采用 Bifrost 架构的第一款 GPU:G71 。然而 G71 在 麒麟 960 和 Exynos 8895 上的表现都非常不佳。
而今年发布的 G72 在性能和效能方面的表现终于达到了之前 Bifrost 架构所承诺的样子。装载 G72 的麒麟 970 和 Exynos 9810 整体效能提升了 100% 。
今天 Arm 宣布了基于 Bifrost 架构的新一代 GPU IP:Mali G76. 它的目标很明确:赶超其他竞争对手。所以它在性能、功耗、面积方面做了很多优化。

Arm 承诺,集成了使用 TSMC 7 纳米工艺的 G76 的 SoC 在性能上可以提升 50%。
仔细对比我们会发现三个关键提升点,第一点是 30% 的性能密度提升。这意味着相同面积的芯片,性能可以提升 30%,或者保持性能不变的情况下,芯片面积可以变得更小。
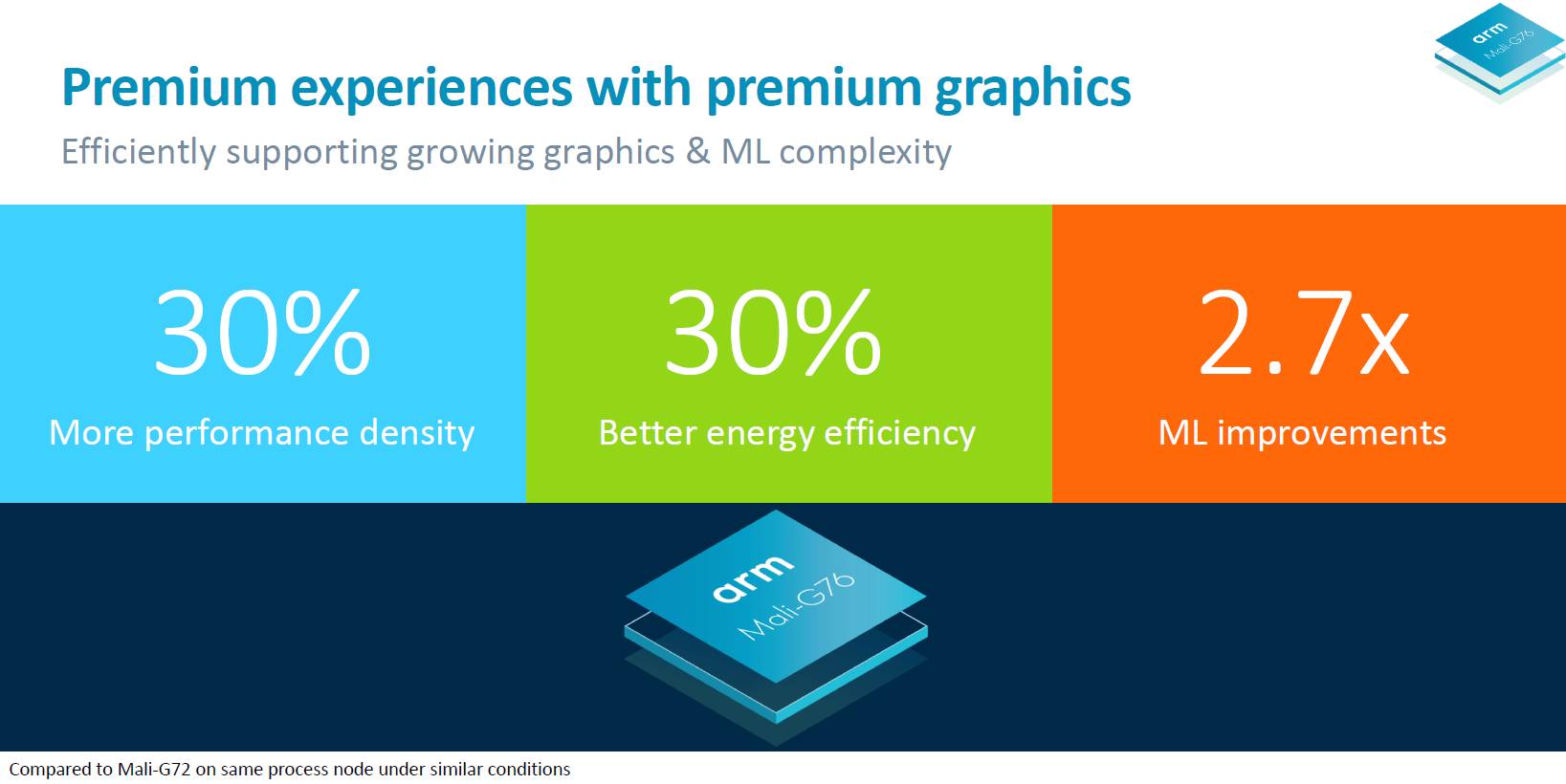
由于功能单元的合并,Bifrost 微架构的效率提升了 30% 。效率是 Arm 当前尤其需要注重的,特别是在过去几年走了不少弯路的情况下,而且竞争对手高通在这期间在 3D 游戏领域发展迅猛。
最后,G76 在机器学习性能提升了 2.7 倍,这得益于往指令集中加入了特定的 8 位点乘(dot product)指令。

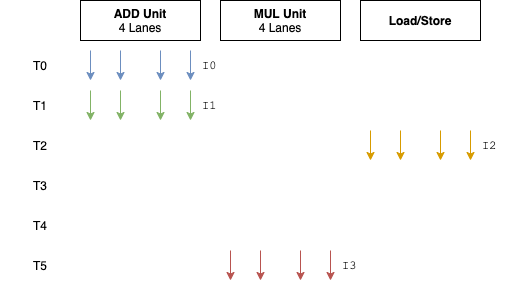
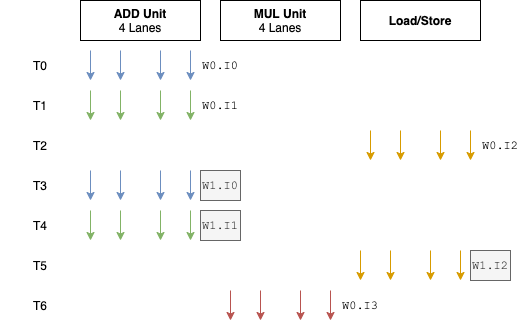
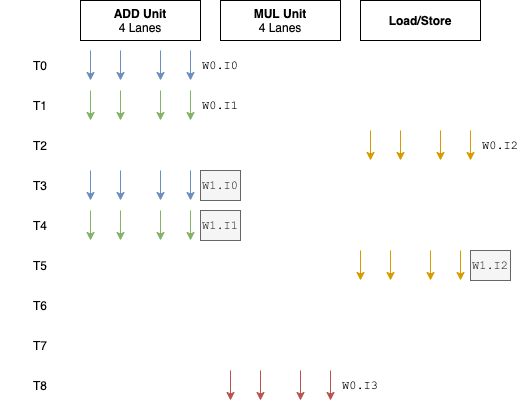
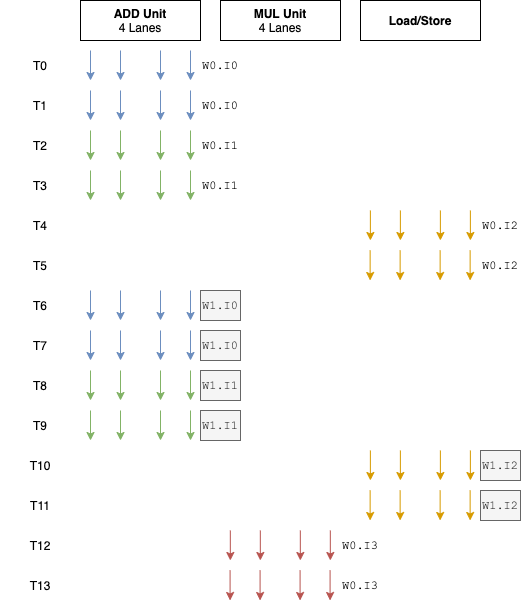
G76的一个很大的改动是:从 4 通道的SIMD单元扩宽为 8 。这意味着每个执行引擎中ALU单元的个数多了一倍。每个通道执行独立的FMA或者ADD/SF流水线。Warp的大小也从 4 变为 8 。总的来说,与其他GPU架构相比之前这种 4 通道设计属于非常窄的了。
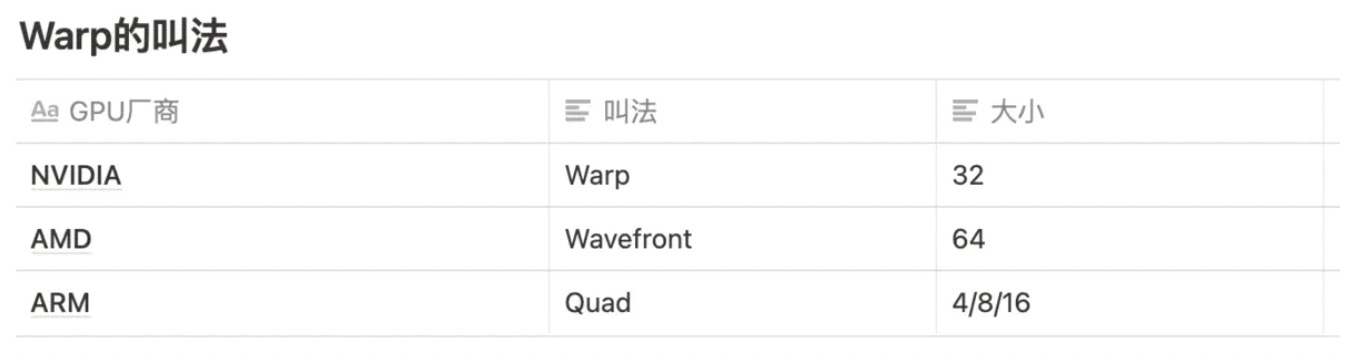
这是一个非常有趣的变动,因为一般Warp的大小对于某个架构而言总是预定义好的,不会像Bifrost这样,中间改动这个值。长期存在的GPU架构中,尤其是PC领域的GPU,Warp的大小很多年都是不变的。NVIDIA自2006年的G80以来,Warp的大小一直是32 。AMD从之前的GCN架构开始至今,Warp的大小一直是64 。
在进一步介绍之前,我们回顾一下Arm的Warp大小采用4的原因。这在《Mali-G71 article from 2016》中有过介绍。
关于Warp的称呼不同的GPU厂商的叫法不一样,具体参看下表。
Bifrost的Warp的大小设置为4是比较有趣的,因为与其他厂商相比(通常16到32),小了很多。
Warp的设计从一定程度上反映了面对面积和性能而做出的不同权衡。如果Warp中线程数量为32,那么32个线程共用一套控制逻辑,而对Bifrost而言,需要8套控制逻辑。但从另一方面看,Warp中线程数量越多,我们越难填充满这些线程。
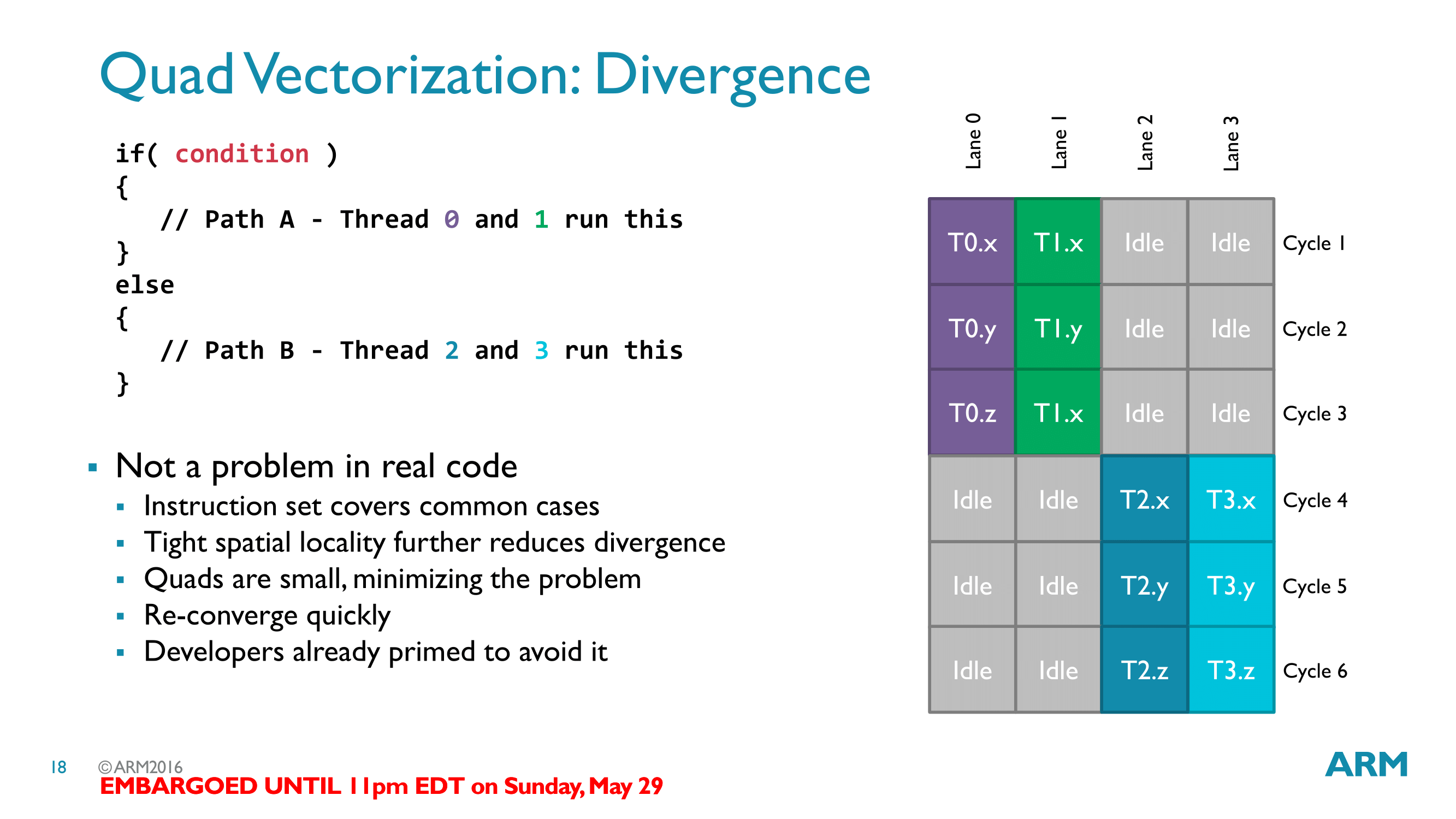
在ARM的GPU设计哲学中,更加注重避免执行卡顿,从Warp大小的设置就可见一二。更小的WARP大小意味着不同线程走向不同分支的概率更低。虽然分支处理很容易,但是这种现象会对性能产生一定影响。
Arm曾说,他们将Warp大小设置为4是为了在出现分支情况的时候尽量减少空闲ALU。理论上,这是一个合理的策略。假设你的程序中存在很多的分支语句,那么确实会有很多时候部分ALU闲置。架构师们在这个问题上花费了很多精力,特别是在桌面级GPU领域。但通常,他们一旦做出了某个选择,那么他们会一直坚持采用,因为开发者也会针对这个问题做自己的优化。
然而,更小的Warp意味着更多的控制逻辑,这样就增加了控制逻辑和ALU的比率。每一个SIMD的执行背后,都需要很多硬件单元来支持,如:缓存、调度单元、数量流控制以及其他硬件单元。这些单元通常功能固定,增加Warp的大小的时候,不需要增加这些支撑的硬件。这便是Mali-G76所作出的权衡。
Arm将4通道SIMD扩宽为8通道的结果是,提升了ALU和控制逻辑的比例。在G76中,在扩宽了SIMD宽度以及增加了执行引擎的数据吞吐量之后,执行核的面积与G72相比只增加了28%。站在整个GPU的角度,这是一个提升面积利用率的选择。

虽然Arm作出这次改变的原因在官方介绍中并未明显提及,但我们的猜测是:Bifrost原先的4通道SIMD的设计是过于热心了(overzealous),在真实代码中不同分支的情况并没有出现的如此频繁,以致于要采用如此少的SIMD通道来优化这样的问题。从Arm得到的说法是:现如今运行在GPU上的代码已经不像G71那时候了。
这样的改变可以在相同面积的芯片上放入更多的ALU。
但这样的改变也需要更加智能的编译器来支持。编译器需要确保8通道的SIMD能够更好的填充任务。而对于上层应用开发者而言,这个改变没有什么影响,因为他们只需要关注标准API以及ARM提供的驱动即可。
加宽SIMD通路的同时,还需要加大Cache以及数据通路。G76每个线程可用的寄存器数量为64,和G72一样,从这个角度来看,寄存器的压力保持不变。

为了匹配8线程的Quad,Arm将纹理带宽以及纹理单元的硬件个数都加了一倍。一个Shader Core可以同时输出2个像素以及2个纹素。新的纹理单元称为“Dual Texture Unit”以区分开之前的纹理单元。

这样做的结果就好像Arm将两个G72的核揉成了一个G76的核。在相同的时钟频率下,通用计算、纹素、像素的吞吐量都翻番了。理论上性能也会相应的提升一倍。整个芯片的面积反而比之前的两个核的面积要少很多。G76在和G72相同性能的情况下,面积是之前的66%,大大提高了面积的使用率。
Arm还在ALU里面加入了int8点乘的支持。这个操作在机器学习中是非常重要的。需要强调的是,虽然之前的Bifrost架构已经支持int8的数据类型(把4个int8打包成一个32位的数据),但G76是第一个把他们利用起来,可以在一个时钟周期内完成一个点乘操作。

这个优化的带来了2.7倍的机器学习的性能提升。这个数字当然只是一个近似值,实际取决于任务的情况。
Arm在机器学习上下了大注,所以明显提升机器学习的算力为他的客户提供了一个新的选择:高效地处理他们的神经网络。
Arm调研后发现,影响扩展性的另一个潜在因素是Tiler,也就是说当核扩展到一定数量后,Tiler会成为性能瓶颈。Tiler成为瓶颈的主要原因是在将Polygon List写回显存的时候速度限制。Arm解决这个问题的方法是从顺序写回变为乱序写回。Arm对这个实现方式持保密态度,大概是因为从顺序写回变为乱序写回不是一件简单的事情。

此外,Arm还详细介绍了该如何使用Tile Buffer,以使很多数据操作都避免访问显存。在某些特定情况下, 允许应用程序将深度缓存当颜色缓存使用。Arm这样做的原因是,存在很多开启多目标渲染而不使能MSAA的情形,不启用MSAA意味着深度的Tile缓存只有部分使用,而Multiple render target迅速占用颜色的Tile缓存。这样做的好处是避免了访问主存的频率,而访问主存通常是一个昂贵的操作。

G76的Local Storage机制也被优化了,主要优化的是处理寄存器溢出的逻辑。GPU会尝试将溢出的数据块组织到一起,以便将来可以更容易的访问到。
从性能上,我们可以说一个G76的核相当于两个G72的核。这也使得G76的配置中,可配置的最大核心数从之前的32个变为20个。

当把核心数都配置为最大,G76相比G72的最高性能提升为25%。需要指出的是,目前还没有使用G71或者G72的厂商将核心数配置为32个,最多的也只有20个G71,那便是Exynos 8895。
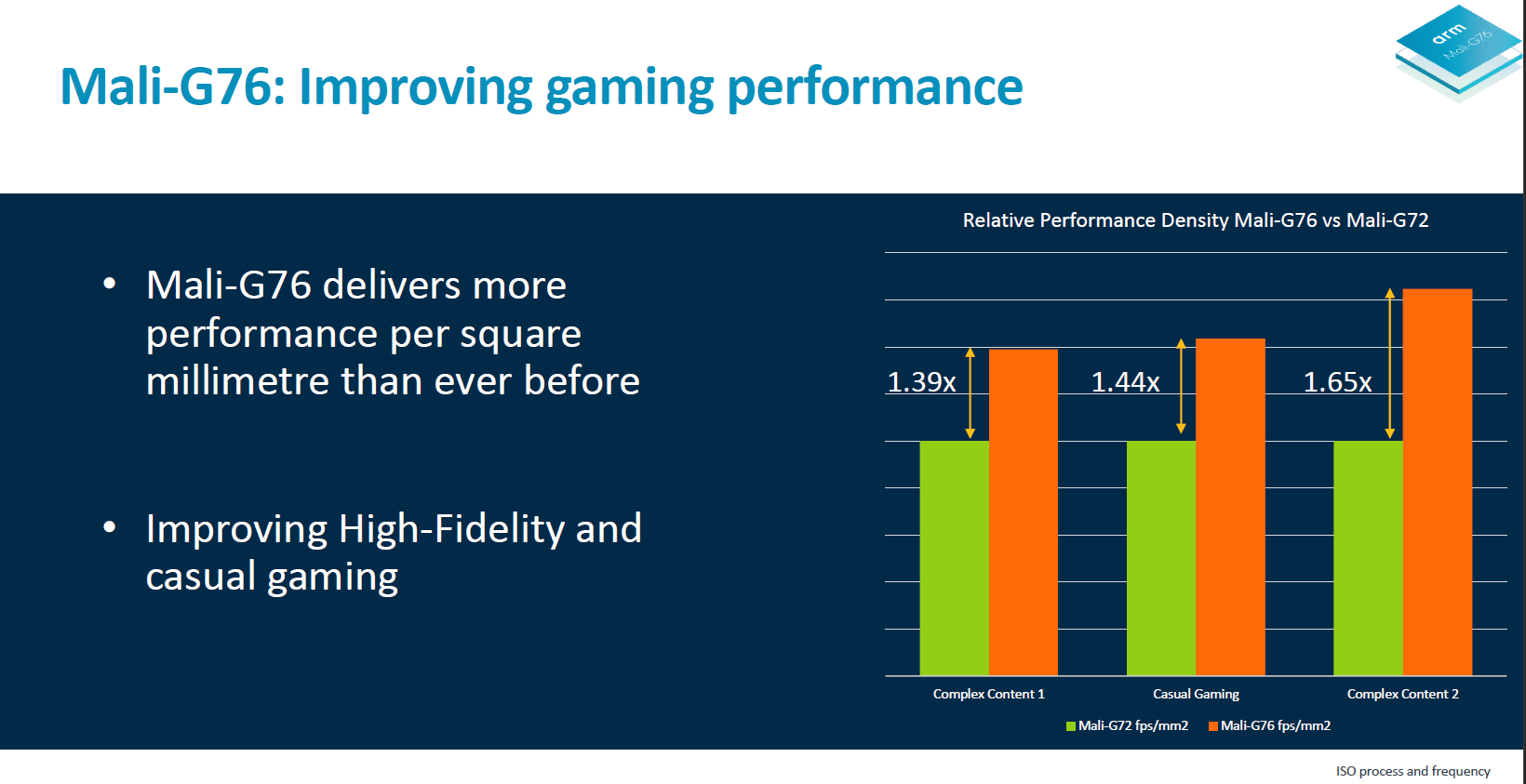
把执行核中的功能单元合并以提升GPU的PPA是十分亮眼的。
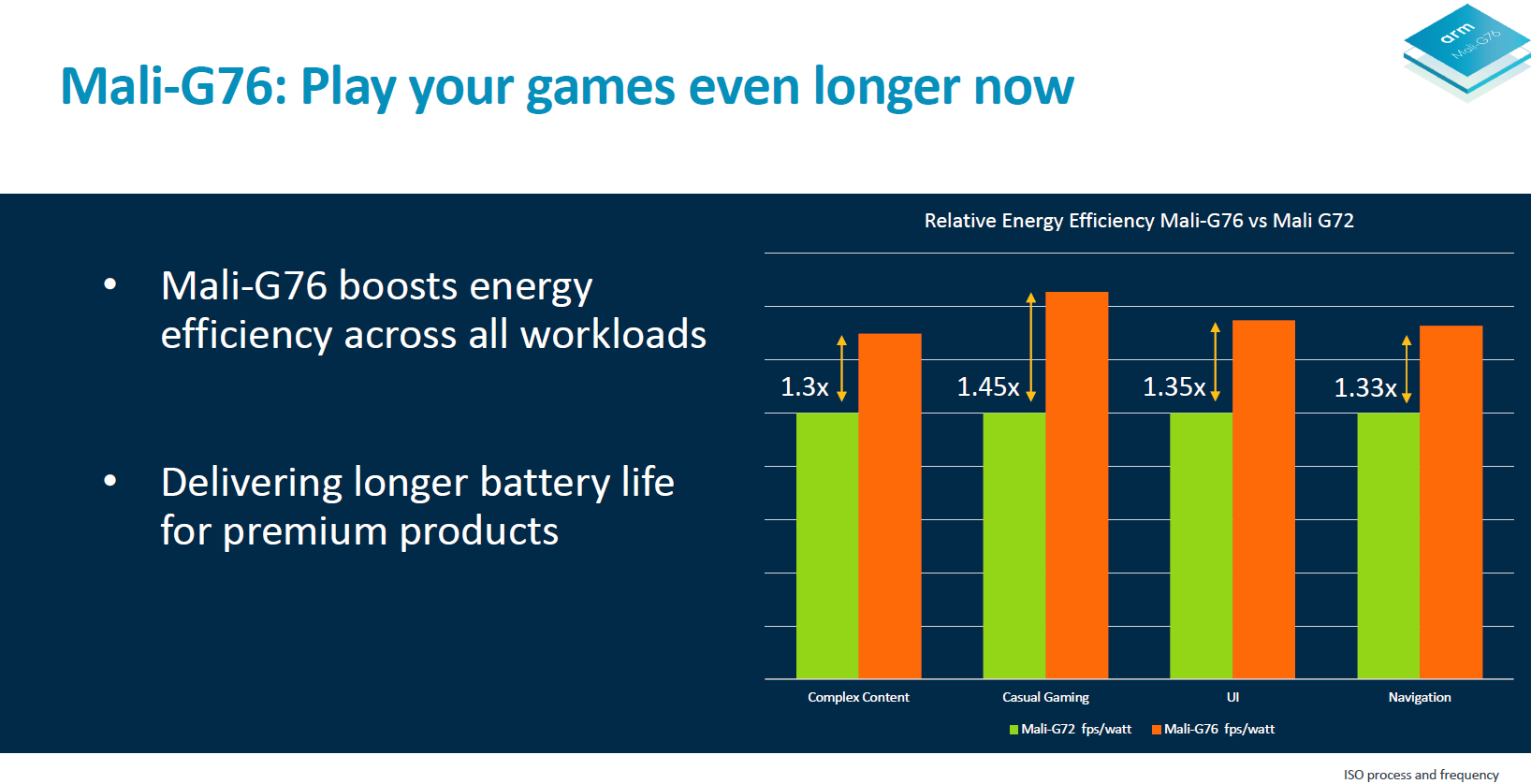
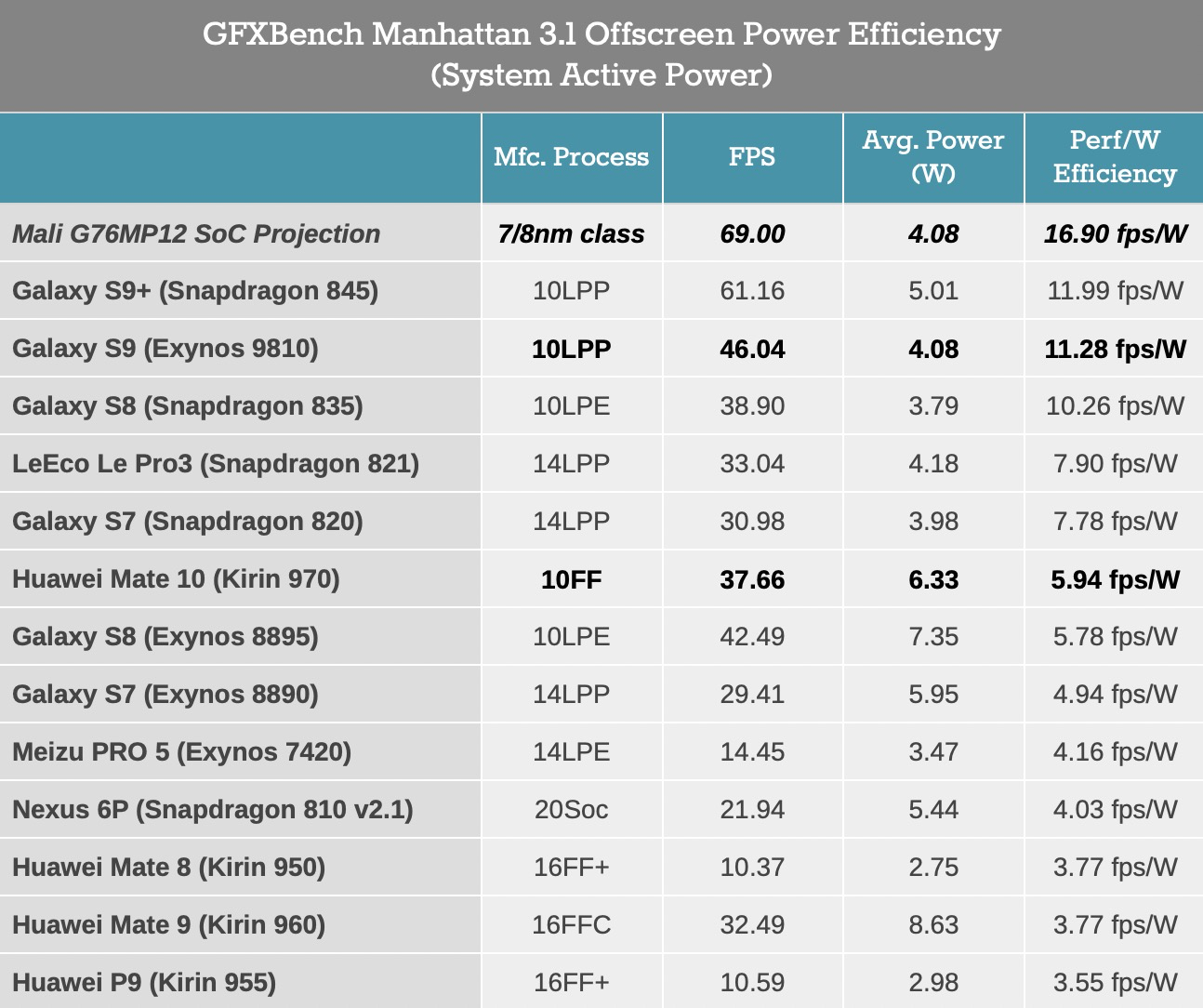
各大GPU IP提供商的竞争从未停止。尽管高通的Adreno 630在能耗效率上变现不佳,但仍然可以在明年发布的下一代中弥补,更别提性能上的提升,这将帮助高通重新获得GPU IP的领导地位。
总结一下,Mali-G76在相同面积和功耗的情况下性能提升了30%。这是一个不错的表现。尽管这能很大提升Mali系列GPU的竞争力,但是还不足以赶超其竞争对手。
微架构的变化方面,Arm将核合并的选择十分不错。当前Arm的核是可配置的,这是一把双刃剑。一方面,这给了客户更多选择,但也产生了不可避免的设计上的冗余。
Mali-G76证明了改进的方法之一可以是去掉冗余的控制逻辑。Arm推出了一款旗舰SoC,搭载了12个核,而我认为核数太多了。反观4核的Adreno 540、2核的Adreno 630、3核的Apple A11 GPU,不难理解为什么Mali在功耗和面积上落后这么多了。我期望Mali可以进一步将每个核中的计算资源提升,这样也许可以进一步提升性能,从而减小和其他竞争对手之间的差距。